中文乱码问题分析及解决策略
在现代数字通讯中,中文乱码现象屡见不鲜,特别是在传输、文本编辑和数据交换的场景中,常常会遇到“中文乱码一区”的问题。国际化和多语言环境的普及,了解并解决中文乱码问题显得尤为重要。本文将深入探讨中文乱码的成因及其应对攻略,帮助用户轻松这一困扰。
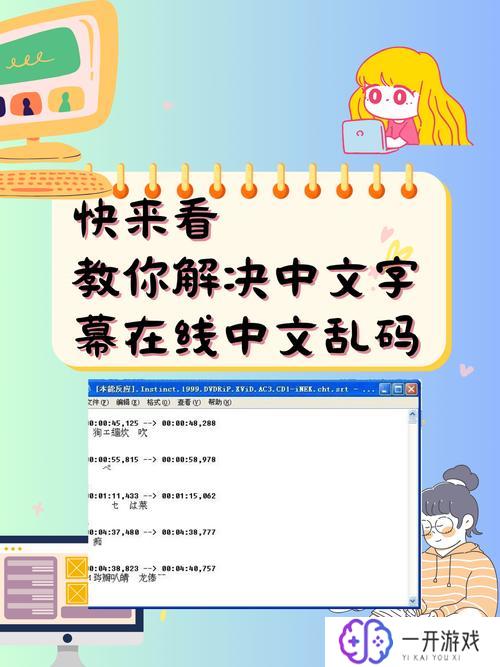
什么是中文乱码?
中文乱码通常指在数据传输或文件保存过程中,中文字符由于编码不一致或不支持导致的显示错误。例如,当一个使用UTF-8编码的文本文件在使用GBK编码的编辑器中打开时,可能出现一些不明的符号或乱码。这不仅影响了信息的传递,更可能导致误解和工作效率的降低。
中文乱码的原因
中文乱码的问题主要源于编码方式的不同。不同的系统和应用程序可能会采用不同的字符编码格式,如UTF-8、GB2312、GBK等。当这些编码格式不匹配时,就会出现乱码现象。传输过程中的数据截断或错误也可能导致字符信息的丢失或变更,从而引发乱码。
如何解决中文乱码问题?
解决中文乱码问题,要从源头入手,明确使用的编码格式。在处理文本的过程中,建议遵循以下几个原则:
- 统一编码规范:在团队协作中,确保大家使用相同的编码标准,建议优先使用UTF-8,因为它具备更广的兼容。
- 文件格式标识:在保存文件时,明确标识文件的编码格式,并在打开文件时选择正确的编码方式。
- 使用专业工具:使用文本编辑器或数据处理工具时,选择支持多种编码格式的工具,以便应对不同文件的兼容问题。
实用的乱码解析技巧
在遇到中文乱码时,以下技巧可以帮助识别和解析:
- 编码检测工具:可以使用如Notepad++等文本编辑器中的编码查看功能,来识别文件当前的编码,并尝试切换至合适的编码格式。
- 转换工具:使用字符编码转换工具来测试和转换乱码文本的编码方式,找到原始文本。
- 逐步排查:如果乱码依旧存在,尝试将文本分段处理,逐步排查是哪个环节出了问题。
与展望
中文乱码问题虽然看似小事,但在信息化的今天,其影响不可小觑。了解中文乱码的成因与解决策略,用户可以更有效地处理相关问题。技术的发展,未来可能会有更智能的工具和方法来解决乱码问题,使得跨语言沟通更加顺畅。希望每一位用户都能在这个多元化的数字世界中,畅享无障碍的信息交流。



















